ためすう
vector::front, vector::back を使ってみる (C++)
2020-07-08確認環境
$ g++ --version
g++ (Homebrew GCC 9.2.0) 9.2.0
Copyright (C) 2019 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.調査
test.cpp
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v = {5, 3, 2, 9, 8};
cout << "v.front(): " << v.front() << endl;
cout << "v.back(): " << v.back() << endl;
// インデックス直接指定でもできる
cout << "v[0]: " << v[0] << endl;
cout << "v[v.size() - 1]: " << v[v.size() - 1] << endl;
}出力結果
v.front(): 5
v.back(): 8
v[0]: 5
v[v.size() - 1]: 8参考
multiset を使ってみる (C++)
2020-07-07確認環境
$ g++ --version
g++ (Homebrew GCC 9.2.0) 9.2.0
Copyright (C) 2019 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.調査
test.cpp
#include <bits/stdc++.h>
using namespace std;
multiset<int> init() {
multiset<int> s;
s.insert(2);
s.insert(3);
s.insert(2);
s.insert(1);
s.insert(2);
return s;
}
void display(multiset<int> s) {
for (auto v : s) {
cout << v << " ";
}
cout << endl;
}
int main() {
multiset<int> s = init();
cout << "【ケース1】" << endl;
cout << "変更前" << endl;
display(s);
// 3つとも消えてしまう
s.erase(2);
cout << "変更後" << endl;
display(s);
cout << "---" << endl;
cout << "【ケース2】" << endl;
cout << "変更前" << endl;
s = init();
display(s);
cout << typeid(s.find(2)).name() << endl;
s.erase(s.find(2));
cout << "変更後" << endl;
display(s);
cout << "---" << endl;
cout << "【ケース3】" << endl;
cout << "変更前" << endl;
s = init();
display(s);
auto iter = s.lower_bound(2);
cout << typeid(iter).name() << endl;
s.erase(iter);
cout << "変更後" << endl;
display(s);
}出力結果
【ケース1】
変更前
1 2 2 2 3
変更後
1 3
---
【ケース2】
変更前
1 2 2 2 3
St23_Rb_tree_const_iteratorIiE
変更後
1 2 2 3
---
【ケース3】
変更前
1 2 2 2 3
St23_Rb_tree_const_iteratorIiE
変更後
1 2 2 3参考
struct のコンストラクタを使ってみる (C++)
2020-07-06確認環境
$ g++ --version
g++ (Homebrew GCC 9.2.0) 9.2.0
Copyright (C) 2019 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.調査
test.cpp
#include <bits/stdc++.h>
using namespace std;
struct person {
string name;
int age;
// コンストラクタを定義
person(string name, int age): name(name), age(age) {};
};
int main() {
person p("person name", 20);
cout << p.name << endl;
cout << p.age << endl;
}出力結果
person name
20ディレクトリごと差分がないかどうかを調べる
2020-07-05やったこと
拡張子がないファイルを検索します。
調査
ファイル準備
$ ls -lh sample-diff*
sample-diff1:
total 16
-rw-r--r-- 1 hoge staff 4B 7 4 14:21 aaa.rb
-rw-r--r-- 1 hoge staff 9B 7 4 14:21 bbb.rb
sample-diff2:
total 16
-rw-r--r-- 1 hoge staff 21B 7 4 14:25 aaa.rb
-rw-r--r-- 1 hoge staff 26B 7 4 14:24 bbb.rb※ ファイルの中身は省略しますが、bbb.rb の中身に差分があります。
man diff のオプションを見てみます。
-r --recursive
Recursively compare any subdirectories found.$ diff -r sample-diff1 sample-diff2
diff -r sample-diff1/bbb.rb sample-diff2/bbb.rb
2c2
< p 'sample-diff1'
---
> p 'sample-diff2'bbb.rb に差分があることが分かりました。
拡張子がないファイルを検索したい
2020-07-04やったこと
拡張子がないファイルを検索します。
調査
ファイル準備
$ ls -la sample-file/
total 0
drwxr-xr-x 6 hogehoge staff 192 7 4 13:39 .
drwxr-xr-x 4 hogehoge staff 128 7 4 13:52 ..
-rw-r--r-- 1 hogehoge staff 0 7 4 13:38 aaa.rb
-rw-r--r-- 1 hogehoge staff 0 7 4 13:38 bbb
-rw-r--r-- 1 hogehoge staff 0 7 4 13:39 ccc
-rw-r--r-- 1 hogehoge staff 0 7 4 13:39 ddd.php今回は find を使ってやってみます。
find [検索対象ディレクトリ] -type ファイルタイプ -not -name "検索パターン"
$ find ./sample-file/ -type f -not -name "*.*"
./sample-file//bbb
./sample-file//cccファイル名に拡張子がある を . が存在すると言い換えると、. が存在しないファイルを抽出することになります。
MySQL の INSERT ... ON DUPLICATE KEY UPDATE 構文 は、大量のデータを1度に INSERT, UPDATE するという構文です。
しかし、この構文を使っている箇所について、下記の事象が発生しました。
- 意図せず AUTO_INCREMENT が進む
- int で保存できる最大値に達する (カンスト)
- 新しくデータが保存できなくなる
今回は、1. のところについての対処方法の共有をしたいと思います。
INSERT ... ON DUPLICATE KEY UPDATE 構文 について
MySQL :: MySQL 5.6 リファレンスマニュアル :: 13.2.5.3 INSERT … ON DUPLICATE KEY UPDATE 構文
この構文を使えば、1本のSQLで、INSERT、UPDATE を実行することができます。
意図せず AUTO_INCREMENT が進んでしまった理由を調べていたところ、
UPDATE 文になった場合でも、AUTO_INCREMENT が進むらしいということが分かりました。
それでは、検証を始めます。
確認環境
$ mysql --version
mysql Ver 14.14 Distrib 5.6.43, for osx10.13 (x86_64) using EditLine wrapper検証
準備
CREATE DATABASE test;CREATE TABLE `tmp_a` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`uniq` varchar(20) NOT NULL,
`cnt` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `idx01` (`uniq`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;現在の AUTO_INCREMENT を確認します。
mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 1 |
+----------------+
1 row in set (0.00 sec)INSERT 文が発行される場合 (id カラムに値を指定しない)
変更前
mysql> SELECT * FROM tmp_a;
Empty set (0.00 sec)mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 1 |
+----------------+
1 row in set (0.00 sec)実行
mysql> INSERT INTO tmp_a (id, uniq, cnt)
-> VALUES
-> (null,'u1', 1), (null,'u2', 2), (null,'u3', 3)
-> ON DUPLICATE KEY UPDATE
-> uniq=VALUES(`uniq`),
-> cnt=VALUES(`cnt`)
-> ;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0変更後
データが登録されたことが確認できます。
mysql> SELECT * FROM tmp_a;
+----+------+-----+
| id | uniq | cnt |
+----+------+-----+
| 1 | u1 | 1 |
| 2 | u2 | 2 |
| 3 | u3 | 3 |
+----+------+-----+
3 rows in set (0.00 sec)AUTO_INCREMENT も 3 進みました。
mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 4 |
+----------------+
1 row in set (0.00 sec)UPDATE 文が発行される場合 (id カラムに値を指定する)
変更前
mysql> SELECT * FROM tmp_a;
+----+------+-----+
| id | uniq | cnt |
+----+------+-----+
| 1 | u1 | 1 |
| 2 | u2 | 2 |
| 3 | u3 | 3 |
+----+------+-----+
3 rows in set (0.00 sec)mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 4 |
+----------------+
1 row in set (0.00 sec)実行
cnt を 1000 倍にして、更新します。
mysql> INSERT INTO tmp_a (id, uniq, cnt)
-> VALUES
-> (1,'u1', 1000), (2,'u2', 2000), (3,'u3', 3000)
-> ON DUPLICATE KEY UPDATE
-> uniq=VALUES(`uniq`),
-> cnt=VALUES(`cnt`)
-> ;
Query OK, 6 rows affected (0.01 sec)
Records: 3 Duplicates: 3 Warnings: 0変更後
cnt が更新されました。
mysql> SELECT * FROM tmp_a;
+----+------+------+
| id | uniq | cnt |
+----+------+------+
| 1 | u1 | 1000 |
| 2 | u2 | 2000 |
| 3 | u3 | 3000 |
+----+------+------+
3 rows in set (0.00 sec)AUTO_INCREMENT も変更されずそのままでした。
mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 4 |
+----------------+
1 row in set (0.01 sec)これは意図通り。
UPDATE 文が発行される場合 (id カラムに値を指定しない)
変更前
mysql> SELECT * FROM tmp_a;
+----+------+------+
| id | uniq | cnt |
+----+------+------+
| 1 | u1 | 1000 |
| 2 | u2 | 2000 |
| 3 | u3 | 3000 |
+----+------+------+
3 rows in set (0.00 sec)mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 4 |
+----------------+
1 row in set (0.01 sec)実行
mysql> INSERT INTO tmp_a (id, uniq, cnt)
-> VALUES
-> (null,'u1', 1111), (null,'u2', 2222), (null,'u3', 3333)
-> ON DUPLICATE KEY UPDATE
-> uniq=VALUES(`uniq`),
-> cnt=VALUES(`cnt`)
-> ;
Query OK, 6 rows affected (0.01 sec)
Records: 3 Duplicates: 3 Warnings: 0変更後
mysql> SELECT * FROM tmp_a;
+----+------+------+
| id | uniq | cnt |
+----+------+------+
| 1 | u1 | 1111 |
| 2 | u2 | 2222 |
| 3 | u3 | 3333 |
+----+------+------+
3 rows in set (0.01 sec)AUTO_INCREMENT が先に進んでしまいました。
mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 7 |
+----------------+
1 row in set (0.00 sec)ここで少し休憩です。
INSERT ... ON DUPLICATE KEY UPDATE 構文 を使うとき
UPDATE する場合、AUTO_INCREMENT を進めないためには、下記カラムの値を指定する必要があることが分かりました。
id(AUTO_INCREMENT)uniq(DUPLICATE KEY)
INSERT, UPDATE 文が発行される場合
今回の問題発生箇所での使われ方です。
変更前
mysql> SELECT * FROM tmp_a;
+----+------+------+
| id | uniq | cnt |
+----+------+------+
| 1 | u1 | 1111 |
| 2 | u2 | 2222 |
| 3 | u3 | 3333 |
+----+------+------+
3 rows in set (0.01 sec)mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 7 |
+----------------+
1 row in set (0.00 sec)実行
mysql> INSERT INTO tmp_a (id, uniq, cnt)
-> VALUES
-> (1,'u1', 1000), (2,'u2', 2000), (3,'u3', 3000),
-> (null,'u4', 4), (null,'u5', 5), (null,'u6', 6)
-> ON DUPLICATE KEY UPDATE
-> uniq=VALUES(`uniq`),
-> cnt=VALUES(`cnt`)
-> ;
Query OK, 9 rows affected (0.02 sec)
Records: 6 Duplicates: 3 Warnings: 0変更前
登録、更新されたデータは意図通りでした。
mysql> SELECT * FROM tmp_a;
+----+------+------+
| id | uniq | cnt |
+----+------+------+
| 1 | u1 | 1000 |
| 2 | u2 | 2000 |
| 3 | u3 | 3000 |
| 7 | u4 | 4 |
| 8 | u5 | 5 |
| 9 | u6 | 6 |
+----+------+------+
6 rows in set (0.00 sec)6 つ進んでしまいました!!!
mysql> SELECT AUTO_INCREMENT FROM information_schema.tables WHERE table_schema = 'test';
+----------------+
| AUTO_INCREMENT |
+----------------+
| 13 |
+----------------+
1 row in set (0.01 sec)どうやら、登録しようとしているデータ全部を更新しなければ、AUTO_INCREMENT が進むようです。
対処方法
id カラムを削除する
DB を利用している側の制約上、削除できない可能性もありますが、
id カラムを削除すれば AUTO_INCREMENT のことを考えなくて良くなります。
INSERT文とUPDATE文を分ける
UPDATE 文のみであれば、AUTO_INCREMENT が更新されないことが分かったので、
SQL を分割するのが良さそうです。
参照渡しを使ってみる (C++)
2020-05-23確認環境
$ g++ --version
g++ (Homebrew GCC 9.2.0) 9.2.0
Copyright (C) 2019 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.調査
test.cpp
#include <bits/stdc++.h>
using namespace std;
void f1(int *a) {
for (int i = 0; i < 3; i++) {
a[i] *= 2;
}
}
void f2(vector<int> &a) {
for (int i = 0; i < 3; i++) {
a[i] *= a[i];
}
}
int main() {
int a[] {1, 2, 3};
f1(a);
vector<int> b = {1, 2, 3};
f2(b);
// 関数を通すと値が変わっている
for (int i = 0; i < 3; i++) {
cout << a[i] << " ";
}
cout << endl;
for (int i = 0; i < 3; i++) {
cout << b[i] << " ";
}
cout << endl;
}出力結果
2 4 6
1 4 9参考
AtCoderで緑色になりました! からの、思い出の問題ベスト3 と やってきたこと少々
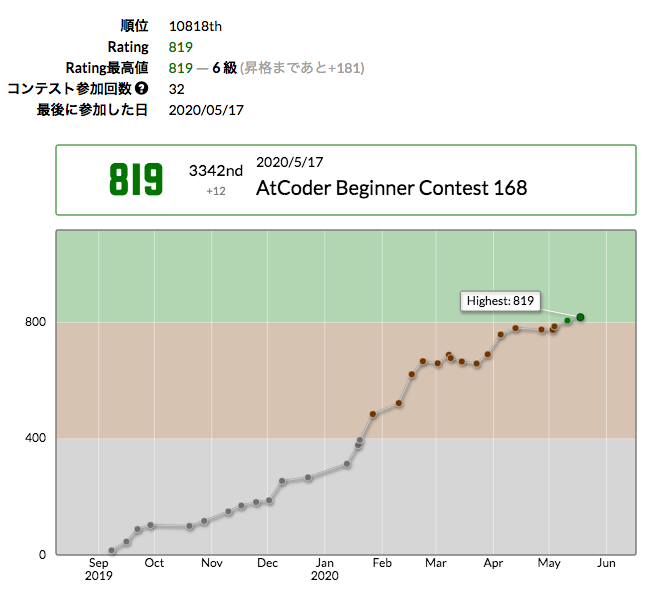
2020-05-192020/05/10 AtCoder Beginner Contest 167 で緑にタッチすることが出来たので、色変記事でも書こうと思います。
(今後、何度か反復横跳びしそうですが、書いちゃいます。)
普段やっていることで、特に変わったことはないので既出の内容かなと思います。
なので、コンテスト中に対峙した記憶に残る問題ベスト3のことから書いてみます。
第3位
初めてコンテスト中に DP を使って AC しました。
雰囲気でやったら、サンプルが合ったので、添字をバグらせまくりながらACしました。
そういえば、この時のコンテストで茶色になりました。
恥ずかしながらコンテスト中に DP を使って解けたのは、これっきり… (頑張ります)
第2位
直前のC問題でド嵌りして、この問題をやるとき時間がほとんどなかったのですが、15m くらいでギリギリ解けました。
(諦めなければ、何とかなることもあるなと思ったりしました。)
ちなみに、この時のコンテストは、パフォーマンスが悪く冷えましたが、 冷えを少なくできたということでこの問題が印象に残っています。
この時、3連続冷え中でした。まあまあ辛かったです。
第1位
はい。まあまあ問題文が短いアレです。コンテスト中、解けませんでした。
問題自体というより、コンテストの時の記憶補正がかかってます。
一見簡単そうに見えるので、解けなかった時のダメージが大きかったです。
そして、このコンテストを機に、問題をきちんと考えてやろうと思い直しました。
それではさらっと、やってきたことのまとめ書いときます。
初期スペック的なもの
- 大学受験で数学を勉強したので、嫌いではない(※ 得意ではない)
- 考えるのは好き(※ 得意ではない)
- 競争はあんまり好きではない (※ 本当かな?)
やってきたこと
ABC A ~ B問題 の灰diff, 茶diff
- C++ を馴染ませるのに役立ちました。
ABC C問題 の ~ 緑diffあたりまで
- 解説AC が増えてきました。復習キューにまだ溜まっています。(早く消化します)
-
- 神資料。蟻本は密度濃すぎるので、辞書みたいに使うのがいいのかなと思いました。類題が載ってて便利。
レッドコーダーが教える、競プロ・AtCoder上達のガイドライン【中級編:目指せ水色コーダー!】 - Qiita
- 神資料。全員読むべき。精選100問は後20問くらい残ってます。
Twitter
- 最初、Twitter 始めた時、自分より若くて強い人がいっぱいいて、今も競プロ界隈にビビってます。そして、夜型がやけに多い気がしました。
その他、お世話になっているもの
- AtCoder Problems
- 神サイト。Virtual Contest もできるし、問題の diff も載っているので、精進するときはこのサイト必ず使ってます。
最後に
緑にタッチするまで、遠かったです。
次の目標は安定して、1000パフォーマンスを出すことかなあと思ってます。
無理せず頑張ります。
競プロ楽しい。
isinf を使ってみる (C++)
2020-05-17確認環境
$ g++ --version
g++ (Homebrew GCC 9.2.0) 9.2.0
Copyright (C) 2019 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.調査
数値が無限大(infinity)であるか判定する。
test.cpp
#include <bits/stdc++.h>
using namespace std;
int main() {
double tmp = 1e100000 / 1e-10;
cout << INFINITY << endl;
cout << std::numeric_limits<float>::infinity() << endl;
cout << tmp << endl;
cout << "-- inf --" << endl;
cout << isinf(INFINITY) << endl;
cout << isinf(std::numeric_limits<float>::infinity()) << endl;
cout << isinf(tmp) << endl;
cout << "-- not inf --" << endl;
cout << isinf(0) << endl;
cout << isinf(100) << endl;
}出力結果
inf
inf
inf
-- inf --
1
1
1
-- not inf --
0
0参考
みなさんは、どんなときに MySQL で Unique 制約をつけるでしょうか。
「必要ならつける!」が答えなのですが、どんな時に必要でしょうか。
今回は、「MySQL で Unique 制約をつける場面はどんなときか」というのを考えてみたいと思います。
Unique 制約とは
あるテーブル内のカラムのデータが1つであることを保証します。(一意性)
Web アプリケーションの場合で考えてみる
Web アプリケーション (Rails) でデータの一意性を保証したい場合
- Web アプリケーション側 (サーバー側) で、データ保存前に検証する
- MySQL 側に Unique 制約をつける
で実現すると思います。
さて最初の問いである「MySQL で Unique 制約をつける場面はどんなときか」の答えとして、
- Web アプリケーション側 (サーバー側) で、データ保存前に検証する
さえ満たしていれば、
- MySQL 側に Unique 制約をつける
は不要でしょうか。いや必要です。
必要になるケースについて見ていきましょう。
確認環境
$ rails --version
Rails 5.2.3
$ mysql --version
mysql Ver 14.14 Distrib 5.6.43, for osx10.13 (x86_64) using EditLine wrapper検証
準備
MySQL
CREATE TABLE `hoges` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`uniq_test1` int(11) DEFAULT NULL,
`uniq_test2` int(11) DEFAULT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_test2` (`uniq_test2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4INSERT INTO hoges VALUES (null, 11111, 22222, NOW(), NOW());app/models/hoge.rb
class Hoge < ApplicationRecord
validates :uniq_test1, uniqueness: true
validates :uniq_test2, uniqueness: true
validate :hoge
def hoge
sleep(5)
end
endWeb アプリケーション側 (サーバー側)では、uniq_test1、uniq_test2 ともにデータ保存前に検証します。
今回は、rails console でモデルを create します。
$ rails c
Running via Spring preloader in process 12528
Loading development environment (Rails 5.2.3)
irb(main):002:0> ActiveRecord::Base.transaction do
irb(main):003:1* Hoge.create(uniq_test1: 5, uniq_test2: nil)
irb(main):004:1> end
(1.9ms) BEGIN
Hoge Exists (6.3ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test1` = 5 LIMIT 1
Hoge Exists (9.9ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test2` IS NULL LIMIT 1
Hoge Create (4.0ms) INSERT INTO `hoges` (`uniq_test1`, `created_at`, `updated_at`) VALUES (5, '2020-03-09 16:42:39', '2020-03-09 16:42:39')
(6.9ms) COMMIT
=> #<Hoge id: 6, uniq_test1: 5, uniq_test2: nil, created_at: "2020-03-09 16:42:39", updated_at: "2020-03-09 16:42:39">処理のおおまかな流れはこんな感じです。
- MySQL の transaction 開始
- データの一意性検証
- MySQL の transaction 終了 (ここでデータが作られる)
問題になるのはほぼ同時に処理が実行されたときです。
MySQL に Unique キー制約なし (悪いパターン)
コンソール1
$ rails c
Running via Spring preloader in process 12742
Loading development environment (Rails 5.2.3)
irb(main):001:0> ActiveRecord::Base.transaction do
irb(main):002:1* Hoge.create(uniq_test1: 5, uniq_test2: nil)
irb(main):003:1> end
(2.2ms) SET NAMES utf8mb4, @@SESSION.sql_mode = CONCAT(CONCAT(@@sql_mode, ',STRICT_ALL_TABLES'), ',NO_AUTO_VALUE_ON_ZERO'), @@SESSION.sql_auto_is_null = 0, @@SESSION.wait_timeout = 2147483
(1.1ms) BEGIN
Hoge Exists (3.2ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test1` = 5 LIMIT 1
Hoge Exists (1.4ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test2` IS NULL LIMIT 1
Hoge Create (4.3ms) INSERT INTO `hoges` (`uniq_test1`, `created_at`, `updated_at`) VALUES (5, '2020-03-09 16:55:12', '2020-03-09 16:55:12')
(7.9ms) COMMIT
=> #<Hoge id: 7, uniq_test1: 5, uniq_test2: nil, created_at: "2020-03-09 16:55:12", updated_at: "2020-03-09 16:55:12">コンソール2
$ rails c
Running via Spring preloader in process 12757
Loading development environment (Rails 5.2.3)
irb(main):001:0> ActiveRecord::Base.transaction do
irb(main):002:1* Hoge.create(uniq_test1: 5, uniq_test2: nil)
irb(main):003:1> end
(1.8ms) SET NAMES utf8mb4, @@SESSION.sql_mode = CONCAT(CONCAT(@@sql_mode, ',STRICT_ALL_TABLES'), ',NO_AUTO_VALUE_ON_ZERO'), @@SESSION.sql_auto_is_null = 0, @@SESSION.wait_timeout = 2147483
(1.5ms) BEGIN
Hoge Exists (2.0ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test1` = 5 LIMIT 1
Hoge Exists (5.1ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test2` IS NULL LIMIT 1
Hoge Create (5.1ms) INSERT INTO `hoges` (`uniq_test1`, `created_at`, `updated_at`) VALUES (5, '2020-03-09 16:55:13', '2020-03-09 16:55:13')
(49.3ms) COMMIT
=> #<Hoge id: 8, uniq_test1: 5, uniq_test2: nil, created_at: "2020-03-09 16:55:13", updated_at: "2020-03-09 16:55:13">Web アプリケーション側 (サーバー側) をすり抜けてしまいました!!!
MySQL に Unique キー制約あり (良いパターン)
コンソール1
$ rails c
Running via Spring preloader in process 12742
Loading development environment (Rails 5.2.3)
irb(main):001:0> ActiveRecord::Base.transaction do
irb(main):002:1* Hoge.create(uniq_test1: nil, uniq_test2: 77777)
irb(main):003:1> end
(3.7ms) BEGIN
Hoge Exists (1.4ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test1` IS NULL LIMIT 1
Hoge Exists (2.8ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test2` = 77777 LIMIT 1
Hoge Create (3.5ms) INSERT INTO `hoges` (`uniq_test2`, `created_at`, `updated_at`) VALUES (77777, '2020-03-09 16:57:01', '2020-03-09 16:57:01')
(18.2ms) COMMIT
=> #<Hoge id: 9, uniq_test1: nil, uniq_test2: 77777, created_at: "2020-03-09 16:57:01", updated_at: "2020-03-09 16:57:01">コンソール2
$ rails c
Running via Spring preloader in process 12757
Loading development environment (Rails 5.2.3)
irb(main):001:0> ActiveRecord::Base.transaction do
irb(main):002:1* Hoge.create(uniq_test1: nil, uniq_test2: 77777)
irb(main):003:1> end
(7.9ms) BEGIN
Hoge Exists (3.7ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test1` IS NULL LIMIT 1
Hoge Exists (1.8ms) SELECT 1 AS one FROM `hoges` WHERE `hoges`.`uniq_test2` = 77777 LIMIT 1
Hoge Create (5.4ms) INSERT INTO `hoges` (`uniq_test2`, `created_at`, `updated_at`) VALUES (77777, '2020-03-09 16:57:04', '2020-03-09 16:57:04')
(19.1ms) ROLLBACK
Traceback (most recent call last):
2: from (irb):4
1: from (irb):5:in `block in irb_binding'
ActiveRecord::RecordNotUnique (Mysql2::Error: Duplicate entry '77777' for key 'uniq_test2': INSERT INTO `hoges` (`uniq_test2`, `created_at`, `updated_at`) VALUES (77777, '2020-03-09 16:57:04', '2020-03-09 16:57:04'))Web アプリケーション側 (サーバー側) をすり抜けたとしても、MySQL に保存したときに MySQL 側のエラーで弾くことができます。
まとめ
データの一意性を保証する必要があるなら、MySQL に Unique キーをつけましょう!
副次的なメリットとして、Web アプリケーション側 (サーバー側) の実装漏れがあった場合も対処できます。